
Publications
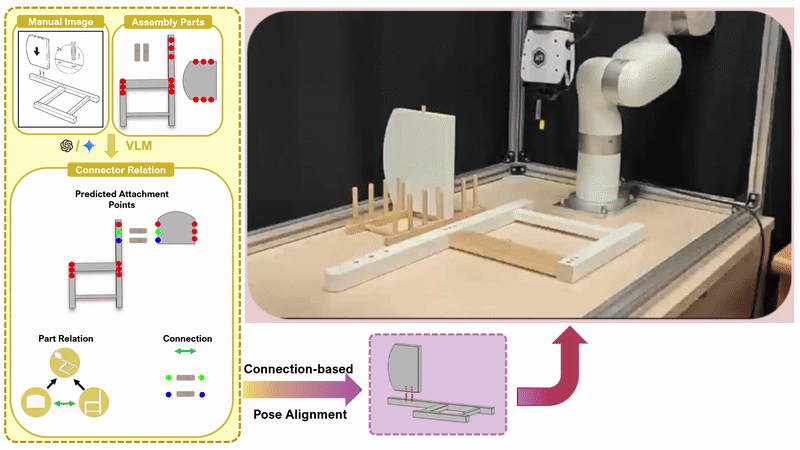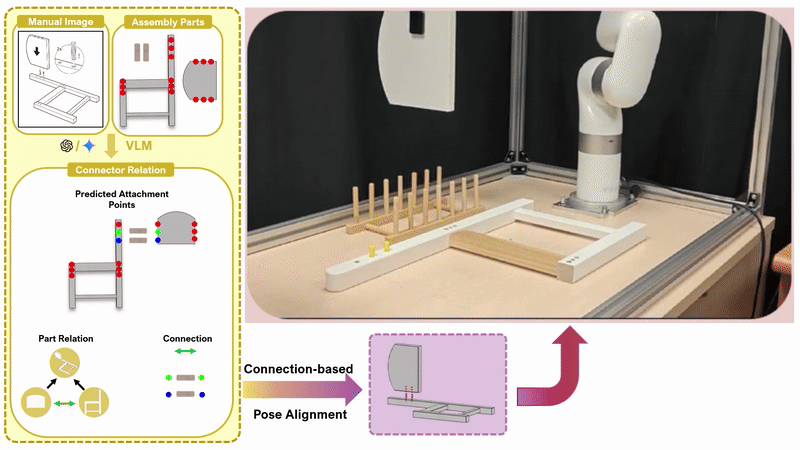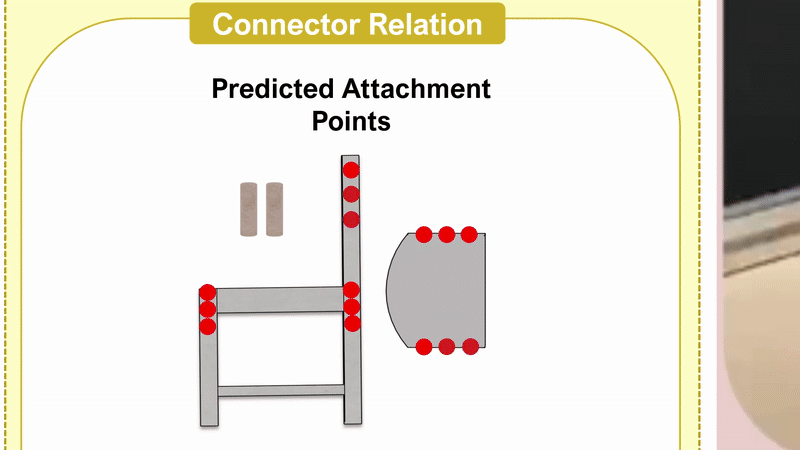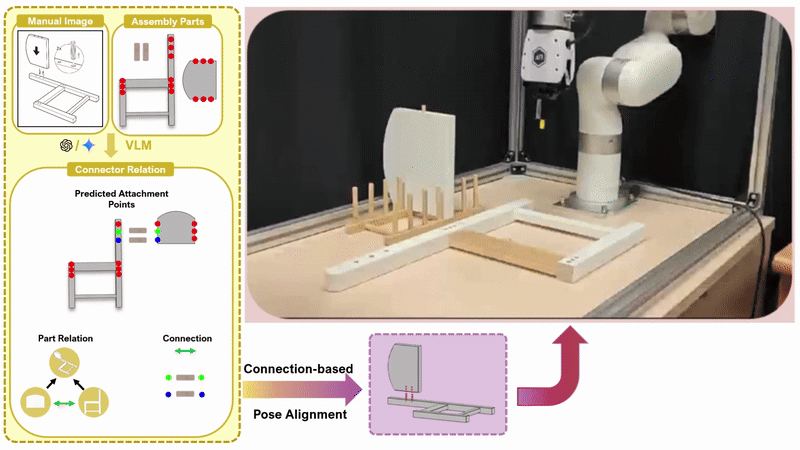
Chenrui Tie*, Shengxiang Sun*, Yudi Lin, Yanbo Wang, Zhongrui Li, Zhouhan Zhong, Jinxuan Zhu, Yiman Pang, Haonan Chen, Junting Chen, Ruihai Wu, Lin Shao
International Conference on Robotics and Automation (ICRA) 2026
[paper] [project page]

Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, Florian Shkurti
Neural Information Processing Systems (NeurIPS) 2025
[paper] [project page]
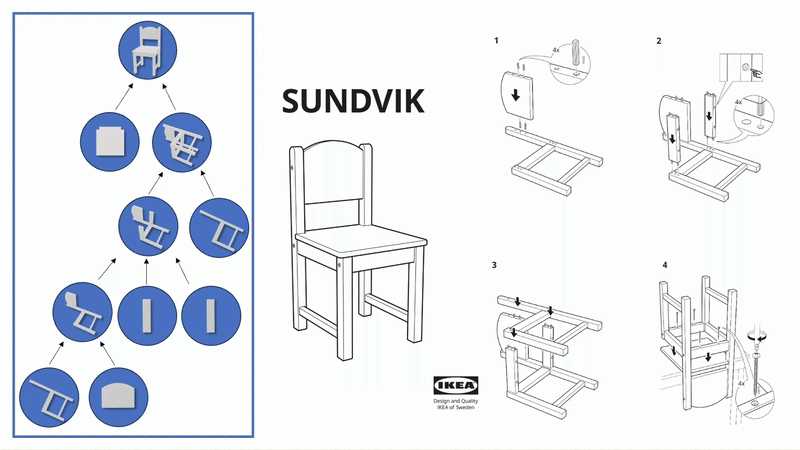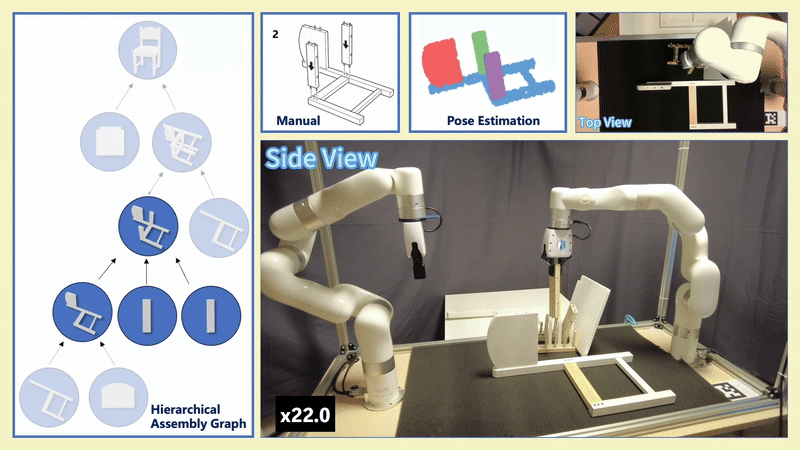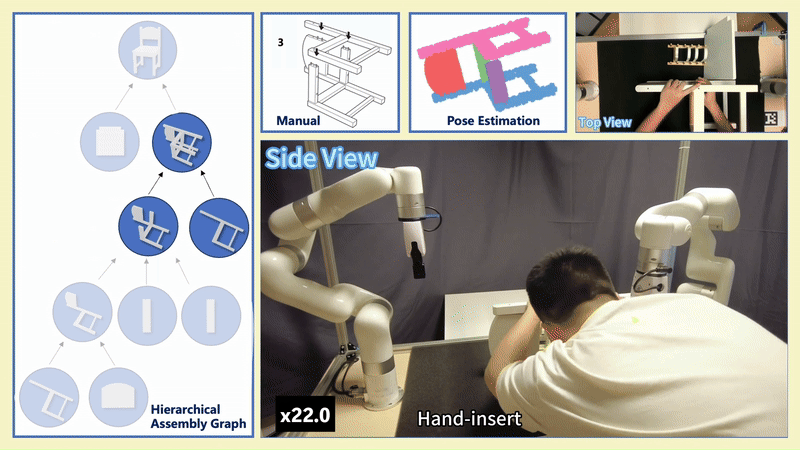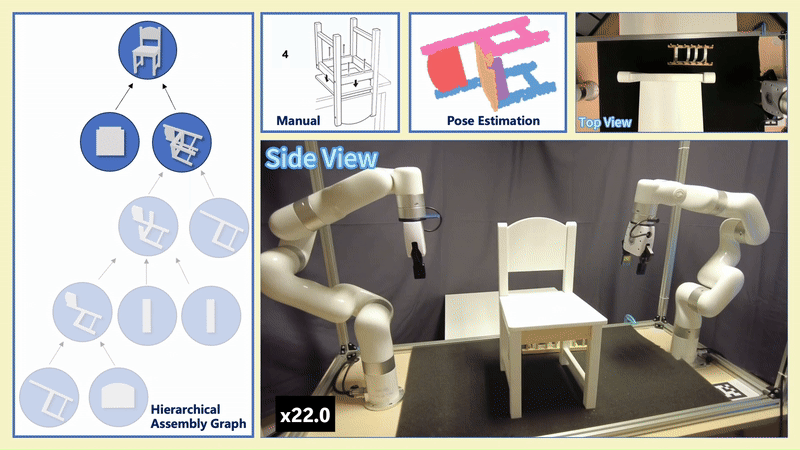
Chenrui Tie*, Shengxiang Sun*, Jinxuan Zhu, Yiwei Liu, Jingxiang Guo, Yue Hu, Haonan Chen, Junting Chen, Ruihai Wu, Lin Shao
Robotics: Science and Systems (RSS) 2025
[paper] [project page]